Data Frame
Another concept in Pandas are called DataFrames. These act similarly to tables and are closely related to Series, much like a column-table relationship in relational databases and are multidimensional arrays. Big data sets can be easily stored inside a Series structure, and the library supports direct conversion from common file types such as both JSON and CSV extensions. The info() method can be used to print info about the dataset, such as total number of columns, rows, non-null values in each column, and datatype of each column, which is extremely useful for knowing if the dataset needs more cleanup.
Creating a DataFrame
Output:
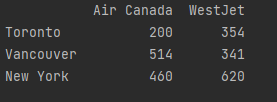
Missing data
If you encounter datasets with missing data, you can use the numpy module to fill in any cells with NaN as a value to what you choose, though most commonly, zero is recommended to avoid contaminating the data.
Output:
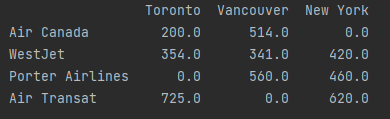
You can also use the interpolate() function to interpolate these values.
The other option as well is to drop any NaN values
Output:

Iteration
You can also loop through a dataset's rows or columns as well. Iterating though a data frame's columns, is fairly straight forward. You can treat the DataFrame as a list, and select a particular index to select a certain column. To iterate and select rows, treat the dataframe like a 2D array and use .iterrows() to loop through.
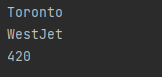
Columns
Output:
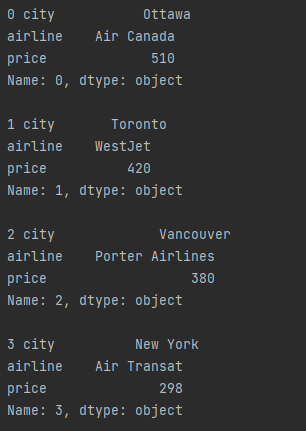
Rows
Output:
Source: Towards Data Science: A Simple Guide to Pandas DataFrames