Code Changes - Edited by KT
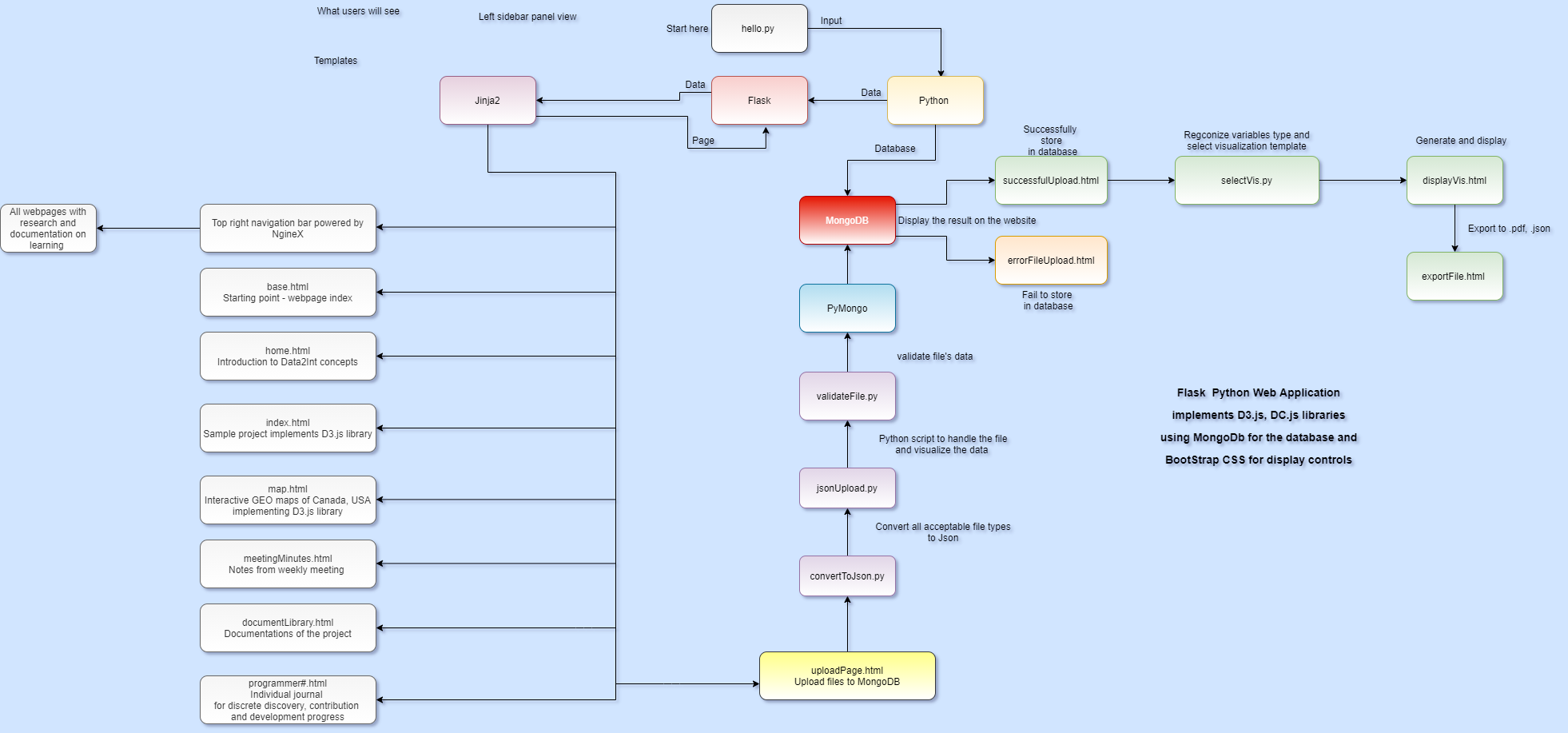
Progress Update
How to start a SSH session using shell script
Note: this method is outdated, although it is necessary that we documented our progressFor your convenience, you can download this .sh file
here
Or you can copy and paste it into your .sh file
#!/bin/bash
USERNAME="{@username}"
IP="{@host}"
PORT="22"
ssh ${USERNAME}@${IP} -${PORT} -t "{cd /your/working/folder/here} ; bash --login"
Why do we choose to convert all files to JSON?
- I decided to convert all files to JSON after uploading then upload to MongoDB. Some changes have been made to the user case diagram so here is a quick review:
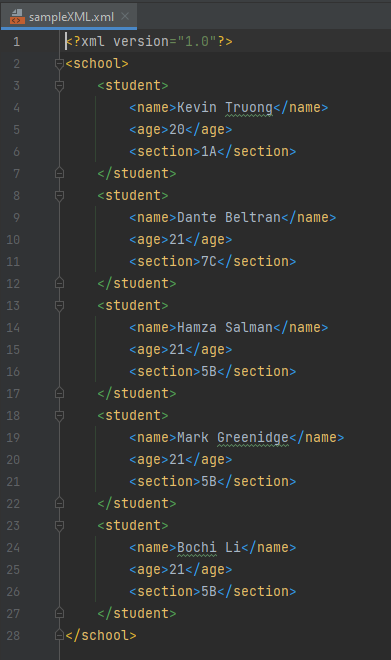
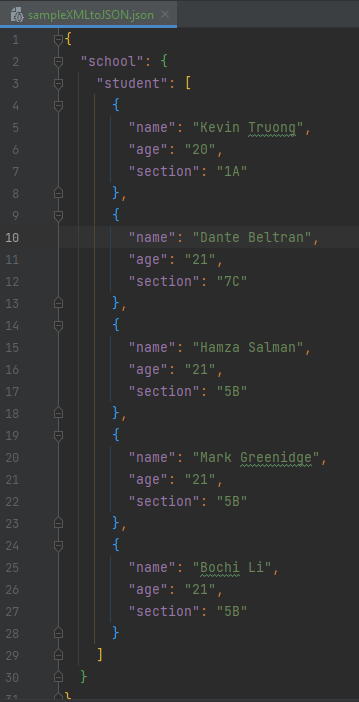
- Here is an example of how to convert XML file to JSON file:
- First, I installed xmltodict library
- Second, I created a new python file called xmlToJson.py
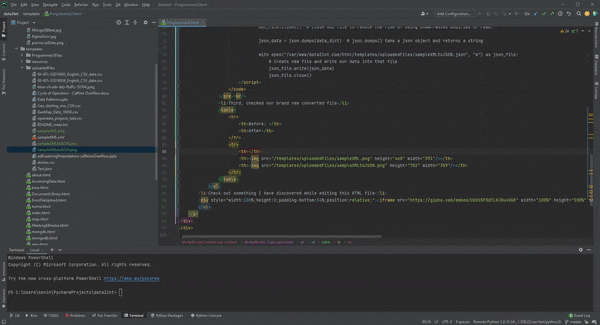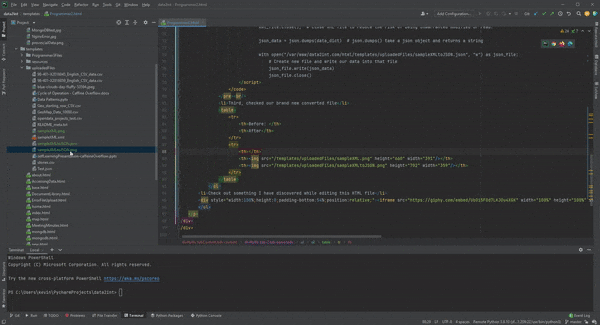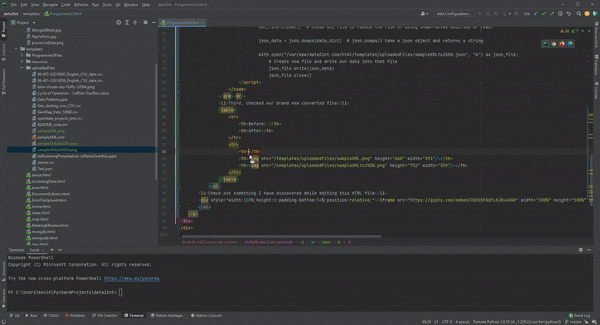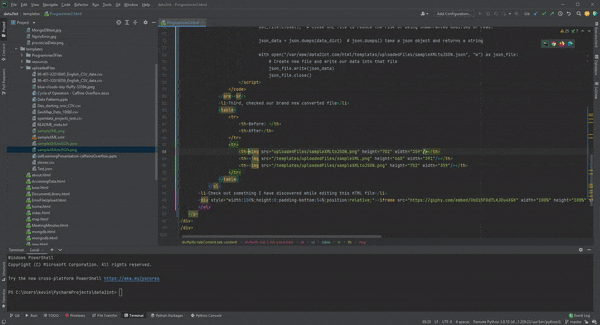
- Third, let's look at our brand new converted file
- Check out something I have discovered while editing this HTML file.
In Pycharm, you can drag and drop your image in your project explorer onto to code editor itself.
pip3 install xmltodict
| Before: | After |
|---|---|
 |
 |
Side notes:
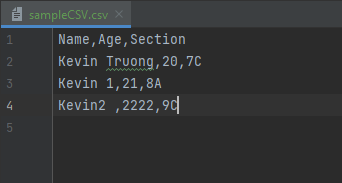
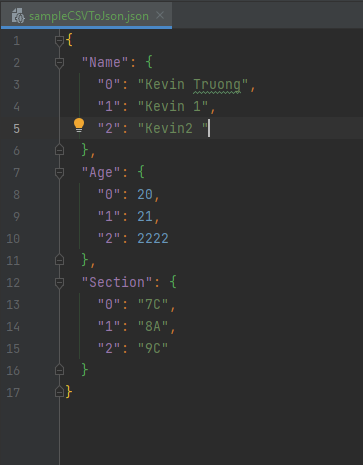
Convert CSV to JSON using Pandas
- First, install pandas library
- Second, I created a new python file called csvToJson.py
- Third, let's look at our brand new converted file
pip3 install pandas
| Before: | After |
|---|---|
 |
 |
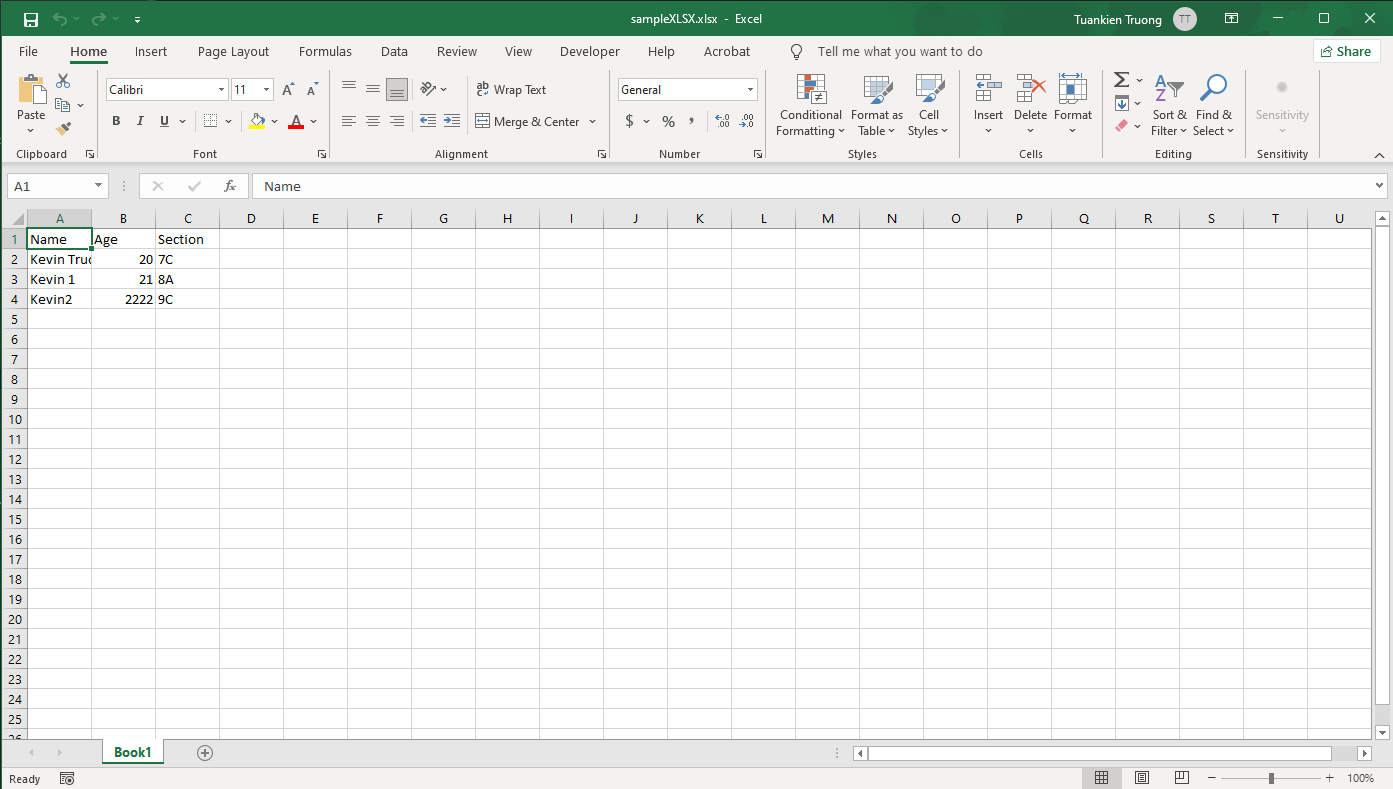
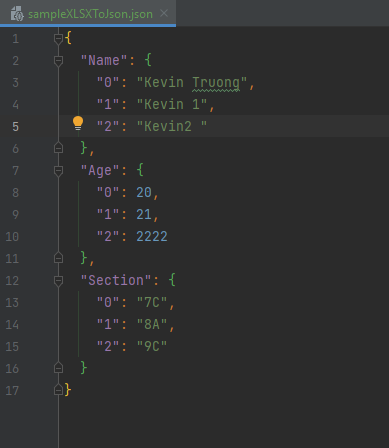
Convert XLSX (Excel) to JSON using Pandas
- First, install pandas library
- Second, I created a new python file called xlsxToJson.py
- Third, let's look at our brand new converted file
pip3 install pandas
| Before: | After |
|---|---|
 |
 |
There is an extended Pandas library, where it uses a Pandas DataFrame to generate profile report quickly and easily.
I highly recommend checking out their Github repository where their documentation is available at
Pandas Profiling Reports
I have created a script where you could generate a profile report from .csv file
This tab shows you how to fetch data from MongoDB
For this website to function properly, you need to upload clean data.
Here is an example of cleaning data from a raw dataset.
You can file this dataset from the Texas Department of Criminal Justice here
The information pf the attributes in this dataset can be found in the table below:
| Attribute's name | Attribute's type | Description |
|---|---|---|
| SID Number | Numeric (Integer) | Security Identifier reference number |
| TDCJ Number | Numeric (Integer) | Full name of the inmate |
| Name | String | Security Identifier reference number |
| Current Facility | String | The current facility the inmate is staying in |
| Gender | Nominal(F: Female, M: Male) | Gender of the inmate |
| Race | Nominal(A: Asian, B: Black, H: Hispanic, I: Indigenous, U: Unspecified, W: White, O: Others) | Category of humankind that shares certain distinctive physical traits |
| Age | Numeric | The current age of the inmate |
| Projected Release | DateTime | Expected discharge in DateTime format |
| Maximum Sentence Date | DateTime | The maximum penalty in DateTime format |
| Parole Eligibility Date | DateTime | The start date of the parole if eligible |
| Case number | String | Unique identifier reference number |
| County | String | A specific region of a state |
| Offence code | Numeric | Offence code |
| TDCJ Offense | String | Texas Department of Criminal Justice Offense charges |
| Sentence Date | DateTime | Trial date |
| Offence Date | DateTime | DateTime of the offence occurring |
| Sentence (Years) | String | The penalty of the inmate in years |
| Last Parole Decision | String | Parole decision |
| Next Parole Review Date | DateTime | DateTime of parole review |
| Parole Review Status | Nominal(IN PAROLE REVIEW PROCESS, NOT IN REVIEW PROCESS, |
Parole status |
Removed attributes and reasons for removal
- Any reference numbers are irrelevant in this study because it does not have meaningful value to our prediction. In this dataset, there are three different attributes that represent reference numbers: SID Number, TDJC Number and Case Numbers. These attributes will be removed from the dataset for analysis purposes.
- The Name attribute is irrelevant because the full name does not have any effect on determining the amount of time an individual is sentenced.
- The Age attribute is relevant, however, this attribute will be replaced by a newly added column that nominalizes the Age Group, more details on this column can be found in part c of this section.
- The Current Facility attribute is relevant, however, this attribute will be transformed to Prison type, more details on this column can be found in part c of this section.
- The County attribute is relevant, however, it will be replaced by Region, more details on this column can be found in part c of this section.
Relevant attributes, newly added attributes and reasons for inclusion
- The Age group attribute description is as follows:
> If age is not given, then NK (no instances)
> If age is less than 12, then Child
> If age is less than 18, then Teen
> If age is less than 50, then Young Adult
> If age is less than or equal to 65, then Senior Adult
>And if age is greater than 65, then Elderly
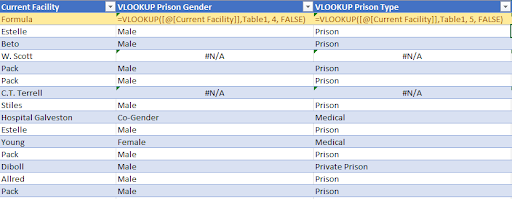
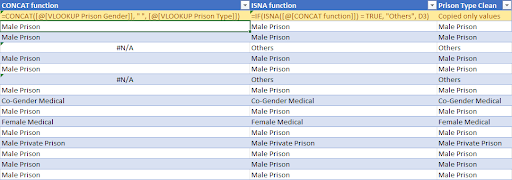
- The Prison type attribute is tricky to classify because there are a lot of inmate facilities. After some research, we found this dataset from the Texas Department of Criminal Justice that provides Facility name, Prison Gender and Prison Type. Then, we use the VLOOKUP function to find the Prison Gender and Type based on the Current Facility attribute, then use the CONCAT function to concatenate the string in both columns. We also use the ISNA function to identify not listed facilities as “Others”. Please refer to the screenshots below for a better understanding.
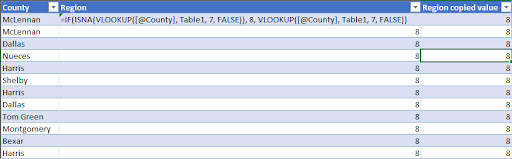
- The Region is very similar to the Prison Type attribute. First, we transform the Region attribute from the dataset from TDJC to a numeric type (I for 1, II for 2, III for 3, IV for 4, V for 5, VI for 6 and Private for 7, NA for 8). Then, we combine VLOOKUP, IF and ISNA functions to get the Region attribute for this dataset. Please refer to the screenshots below for a better understanding.
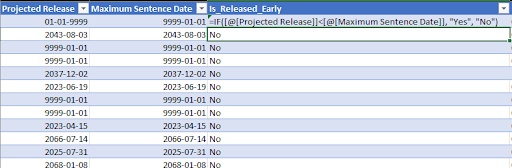
- The Release_Early is relevant because it is the boolean value of the difference between Projected Release and Maximum Sentence Date. There was an issue while trying to calculate the difference between the two dates because the input was a text instead of a date format. To fix this, we can Select the column → Text to Columns → Next → Next → Choose Date Format as “MDY” → Finish. Please refer to the screenshot below for a better understanding.
- Similarly, the Able_to_parole_early is relevant because it is the boolean value of the difference between the Parole Eligibility Date and Maximum Sentence Date.
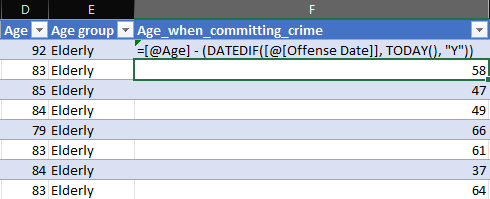
- The Age_when_committing_crime_in_group is relevant because we want to find out at what age they committed their crime. Although their age is important, it is also important to find out when they did such things. To calculate this attribute, we can use the DATEDIF function (by years) to find the difference between Offense Date and TODAY(). Then, we use their current Age to subtract that result to get the age when they committed their crime. Then, we apply the same category (from Age) to the current value.
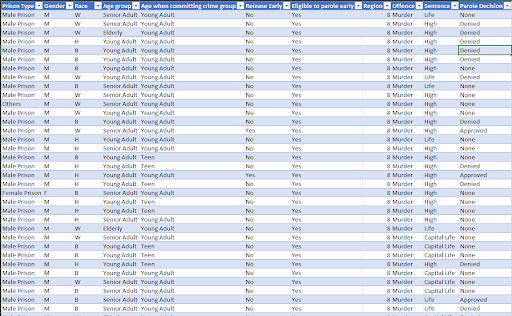
- For the sentenced, we classified them less than 5 would be low, less than 10 is medium, more than 10 is high and everything else is life or capital life, depends on the description
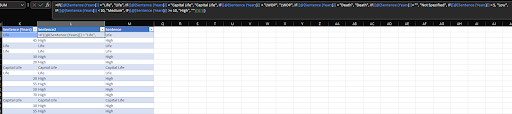
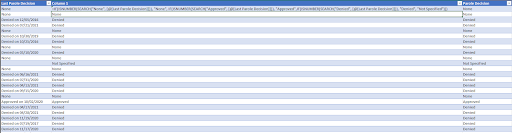
- For Parole Decision, we trimmed to columns parole review to Approved, None, Denied, or Blanks
- For offence code, we categorize them by looking at the first 2 numbers of the offence code. For example, numbers start with '9' will classify at Murder, '10' for kidnapping and so on.
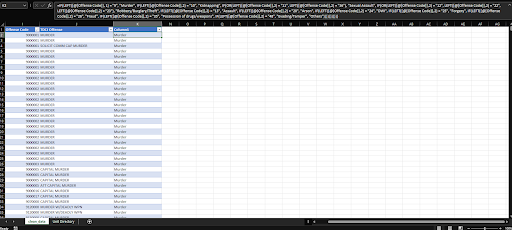
- Let's take a look at the BEFORE and AFTER:
BEFORE
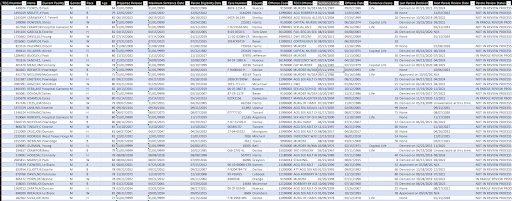
AFTER
Kevin Personal Project
This project uses the dataset from Kaggle.
This dataset is about NFT (Non-fungible token) sale history.
Did you know the most expensive NFT is sold for ~ $532 million? (last updated Dec 1st, 2021).
Check out this article here
In this small little project, my goal is to understand the data, perform data cleansing and provide visualizations to the public!