Code Changes - Edited By HS
Progress Update
-Setup Pycharm IDE to interface with the server.
-Implemented code to upload file to local directory.
This section covers the implementation of the file upload feature.
- Creating the upload page and implementing the file input form:
- Submitting the form with file data and checking it in the main app.py file. Checking if its valid and saving it to the web server:
This section covers Uploading data for the Geo Map.
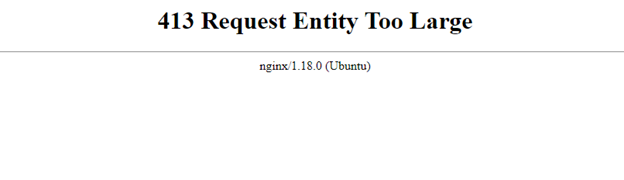
- Issues with file size:
413 Request Entity Too Large error is displayed when trying to upload Stats Can data. The limit needs to be increased in the Njinx.conf file, Reference: Upload Error Info
- Issues with the data:
We were unable to determine a way to properly find an element that could be used for the location element. The CSV that was requested had many subdivisions and went into high details for the different areas. They are using Dissemination area (DA) ids for detailed locations which would not be implementable on the current chart. Reference: Link to the Stat Canada Website

The issue with this however was even with a small data set, the file would not upload. The limit is very low, and it would not cover much of the data.
HTML for GeoMap
JavaScript for GeoMap (hamzaGeoMap.js)
HTML for GeoMap with Divisions
JavaScript for GeoMap with Divisions using database (hamzaGeoMap.js)
The following is the PowerPoint that walks you through the creation of a GeoMap using D3:
View PowerPointStats Can Map Operational:
This map has clickable elements that will prompt you with the 2016 StatsCan Population data for each province. (NOTE: It takes a long time to load)
Use scroll wheel to zoom in and out.
Pickle Python Library
Pickle is a library in python used for serializing and de-serializing Python object structures
This can be very useful if a user is trying to extract a large dataset from a python program.
Having this extracted data can be very useful, not only to make backups, but also to use it for analysis purposes.
An example of this would be if a user had a python program used for machine learning, they could extract this data
used for training the model and also the results produced by the Model itself.
This data can then be used as a backup for the model and also as a data set that can be used to analyze the model.
What data types can be pickled?
- Booleans
- Integers
- Floats
- Complex Numbers
- Strings (normal and Unicode)
- Tuples
- Lists
- Sets
- Dictionaries that are built using other pickle supported data types
Pickle vs JSON
Pickle is very similar to JSON in its functionality, however there are some benefits to JSON. JSON is
language independent unlike Pickle and it is also more secure than Pickle. The advantage to Pickle however
become evident if you are solely using a Python based application as it can take the data from the Pickle
files and reconstruct objects that can be used in your program.
References:
Uploading a JSON File
The following shows how I uploaded a json file to MongoDB using Python.
-
This script would automatically be run when an upload is called on a json file. The data would be uploaded into MongoDB for us to access.
-
We tested this by just implementing it directly to a page and running the script in the main program, but ideally we would have this as a separate script.
-
The result looks like this in MongoDB:

Personal Project: Geo Map Data
For my personal project I will be taking a more in-depth look on how to create GeoMaps.
The goal for this will be to find a way to implement the ability to create GeoMaps that dont conform to regular world maps.
I want to implement the ability to work with unconventional geo data and try to create useful visualizations.
The other thing I want to look into is, how to create GeoJSON files based on custom maps.
For the file upload process our team decided to focus on four main data types: CSV, XSLX, JSON, XML
The upload function in our main python file identifies the file type and redirects it to the correct upload function
so that the data can be uploaded into MongoDB. The following are the four files used to manage the different file type uploads.
D3 Visualizations
I created 2 D3 visualizations that are generated when a user uploads a file. One is a scatterplot and one is a barchart
Data Gathering for Visualizations
The first step was to get a list of columns and analyze which ones were categorical or numeric.
AnalyzeData.py
Then we get the measures and dimensions
Measures
Dimensions
We can also get the measures automatically.
Auto Measures
We also get the user input to see what variables they want to use for their visualizations.
User Input
Displaying Data and Visualizations
we first display the data on the successful upload page. Here the user can view automatically generated
scatter plots using python and an indepth analysis of their data using pandas profiling. Then the user
selects their variables which genertates the D3.js visualizations
Auto Scatter Plots
Successful Upload
Visualizations
Multithreading
For the next steps in this project, one of the biggest recommendation is to implement multithreading. The biggest issue we encountered was efficiency
as a lot of the tasks happening in the backend were very slow and would often take a long time to load for the user. Since we tested a lot of the
capabilities locally this was not an issue that was caught by our team till very late in development. Below is some of the useful information that
we came across during our research.
Flask Multithreading
In order to implement multithreading for flask you have to define it within the main file that runs the program.
The purpose of this is to allow multiple users onto the website at a time and to also hopefully increase efficiency.
Gunicorn Multithreading
Along side Flask Multithreading one useful piece of information may be that you have to define the number of worker
cores for Gunicorn manually in the gunicorn config file. This may be important when it comes to Flask multithreading,
but we are not certain. However one main issue we had was that the threads were running different functions that needed
to communicate with each other to pass data however the threads were not able to. This is not an issue that is prevalent
in local testing, but rather only on the production server.
NOTE: The Gunicorn config is located at: /etc/systemd/system/gunicorn.service And to modify the parameters you have to change the exec start line.
Here is a link to all the multiple settings.
Debugging
In order to debug these issues on the server we setup a simple output file which is placed in the main directory for the
website. One is called the gunicorn-access.log and once is called the gunicorn-error.log file. these files will update with
the console. However since the console is not available on production these can be really beneficial to see if threads are not
communicating because if you have debug messages in different functions, if they get called from different threads, you can
compare the PID(process id) to check what thread they are on and if they are communicating with each other. This was the biggest
issue that our team faced during deployment as tracking down the issue was difficult without a console. however once we had that
we switched it back in the gunicorn config which fixed the issue.